Preprocessing
The preprocessing chain is held together with RabbitMQ message queues. These allow multiple services, functions, duplicate pipelines etc to be using the same real time data. RabbitMQ also has the capability of persisting message queues which would allow a graceful recovery should any preprocessing blocks fail.
The below block-diagram shows how this was used to combine multiple AIS streams across multiple servers. Arrows with white points represent RabbitMQ message queues. It is possible to run the RabbitMQ service on a single machine or to duplicate it across multiple machines (either plain old duplicate or HA node)
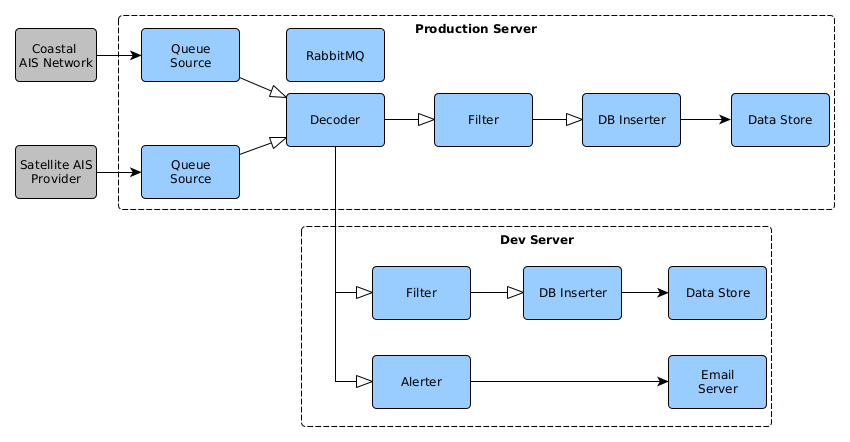
The input to this whole data stream can be from several different sources or a combination thereof. Typically commercial AIS comes in two flavours: data recorded by satellite receivers and data recorded by coastal receivers. There will be some considerations like cost and data rate that might require different processing between the different data types. Data could also come from non-streaming sources like text files. RabbitMQ allows data to be tagged with a routing key that consists of several tags seperated by “.”. A rule of thumb that I’ve been using it to tag the data with least to most specific details.
Example: AIS data that is pulled from a coastal network around Denmark might have the routing key “decoded.ais.coastal.denmark”. This routing key would allow consumers to request RabbitMQ build a queue for them. Using wildcards is also possible! A filter that handles all AIS messages could request data for “*.ais.*” while someone interested in decoded data for Denmark, from any source, could request “decoded.#.#.denmark”.
The AIS-i-Mov micro-service is used to grab AIS data from a source, separate the meta-data from the AIS data and publish this with a configured routing key. The decoder, or some other later step, would pull this data and decode it into a list of key-value pairs.
The standard format for AIS data looks a little something like:
!ABVDM,1,1,,B,13=fod0vQv1B5LgdH:vMAJdB00Sa,0*42
!BSVDM,2,1,8,B,5E@;DN02AO;3<HMOJ20Lht84j1A9E=B222222216O@a@M00HtGQSl`3lQ1DT,0*75
!BSVDM,2,2,8,B,p8888888880,2*7E
!ABVDM,1,1,,B,HF<nO80d4v0HtpN0pvs40000000,2*62
!ABVDM,1,1,,B,B8u:Qa0000DwdMs8?LrDio053P06,0*59
but these do not contain any timestamps. Generally when using commerical or stored data the original producer will include some timestamp, and other metadata, with the AIS data. There isn’t a set standard on how to do this so it varies from source to source:
IMIS Style AIS data
\s:CSIR_000,q:u,c:1620731505,i:|X=0|D=1|T=44327.4781489815|P=10.0.100.6:12113|R=IN|E=10000000000000000000|*48\!AIVDM,1,1,,B,33ku82U000OGsfHH:Uv`9j3J0>@<,0*68
\g:1-2-1159,s:CSIR,c:1620731662,i:|X=1|D=1|T=44327.4683069097|P=10.0.100.6:12113|R=IN|*46\!AIVDM,2,1,9,A,53Fted42?II@D5=:2204h8Ub2222222222222216:`?1>5D80B0hDh@S0CPh,0*3F
\g:2-2-1159*51\!AIVDM,2,2,9,A,H8888888880,2*5D
This type of data prepends the metadata before each AIS message on each row. There is some mapping as to what each field means but you would have to read the data provider’s datasheet to figure it out.
The AIS decoder makes use of an open source library to decode the data.
Timestamp, library, output style, OGC moving feature https://www.ogc.org/standards/movingfeatures
Filtering data is often a requirement. Raw AIS data has a nasty habit of filling up DB’s without providing any additional context. A vessel at rest in a harbour can easily send thousands of messages without any real change showing. Filters can also limit a dataset to a region of interest. A port might not be interested in deep ocean data.
These filters are implemented in python using a simple rule check. If there isn’t much change in the lat/lon, timestamp or the message is outside the area of interest, drop it. Else republish it on RabbitMQ.
Inserting rows into the DB comes with an overhead cost. To minimise this bulk inserts should be done instead of row-by-row inserts. The DB-inserter container used psycopg2 to do the inserts into PostgreSQL. The bulk insert period is configurable but defaults to 5 seconds. In this case if the difference between the first message, in a insert group, and the most recent message is greater than 5 seconds, the group is inserted into the DB and the inserter starts gathering fresh messages.
There is one downside to this method; when the AIS message stream is interrupted messages can become stuck in the inserter container until a new message, with a timestamp 5 seconds older than the first message, is ingested and the group inserted. In practice this isn’t really a big deal though.